AI is generating unprecedented volumes of code daily. Modern development workflows enable scenarios where a simple "@claude" comment triggers an autonomous agent that deploys, analyzes your codebase, implements a fix, and creates a comprehensive pull request. LLMs have become integral to code review processes, architectural planning, documentation generation, and numerous other development activities across the industry. But as AI code contributions scale, we need to ask a fundamental question: Do meaningful, observable differences exist between AI-written and human-written code?
The answer matters. Code quality, maintainability, and architectural decisions have long-term implications for software projects. Understanding the characteristics that distinguish human from AI authorship can inform better tooling, improve code review processes, and help us critically evaluate AI's role in software development. Moreover, as AI models continue to improve, establishing baseline measurements of current capabilities provides context for future progress.
This project compares human-written code against code generated by three prominent AI models: ChatGPT, DeepSeek Coder, and Qwen. Rather than relying solely on surface-level metrics, our approach combines traditional software engineering measurements with modern machine learning techniques using semantic embeddings and dimensionality reduction.
We analyzed the OSS-forge/HumanVsAICode dataset, which contains equivalent Python and Java implementations authored by humans and generated by AI models. The models used are ChatGPT, DeepSeek, and Qwen. Our methodology employed a two-stage analysis pipeline:
Structural Analysis: We extracted traditional code metrics including lines of code, comment density, indentation patterns, cyclomatic complexity, and variable naming conventions. These metrics capture the observable, measurable characteristics of code style and structure.
Semantic Analysis: Using OpenAI's text-embedding-3-small model, we generated high-dimensional semantic embeddings for each code sample, then applied UMAP dimensionality reduction to visualize clustering patterns. This approach reveals deeper semantic and stylistic patterns that transcend individual metrics.
The combination of these techniques provides both granular, interpretable metrics and holistic pattern recognition, allowing us to recognize any observable differences between human and AI generated code.
The complete code and methodology are available on GitHub at https://github.com/correlltechnologies/human-vs-ai-code-analysis. The repository includes scripts and instructions to reproduce these findings or apply them to your own datasets.
1. Lines of Code (Not Significant)
Both humans and AI wrote roughly the same number of lines to solve the same problems, about 8-10 lines on average. This was surprising because there's a common belief that AI writes way too much code to solve simple tasks. DeepSeek was the exception, writing slightly longer solutions (around 12 lines), but ChatGPT and Qwen matched human length almost exactly.
2. Line Length (Highly Significant)
Humans write denser lines. The average human line was about 40 characters, while AI lines averaged around 35 characters. Humans seem comfortable cramming more logic into a single line, while AI breaks things down into smaller, more digestible pieces. All three AI models (ChatGPT, DeepSeek, Qwen) wrote similarly short lines, clustering around 30-35 characters. Human developers showed way more variety, highlighting the fact that everyone has their own style and experience.
3. Complexity (Highly Significant)
We measured cyclomatic complexity, which basically means "how many different paths can your code take?" Both humans and AI wrote code with similar complexity levels, around 25-35 decision points per 100 lines, with a surge at 50 decision points per 100 lines. However, human code had more variance. On the other hand, AI models were very consistent. All three clustered towards the mean, besides Qwen’s surge at 50 per 100 LOC.
4. Indentation Depth (Highly Significant)
Indentation depth measures how many layers deep your code goes. This was one of the largest observable differences. Human code ranged from 2 levels deep all the way up to 13 levels, with an average around 7. AI code rarely went past 8 levels and averaged around 4.
DeepSeek and Qwen were particularly flat (3-4 levels), while ChatGPT allowed slightly more nesting (4-5 levels), but still way less than humans.
5. Average variable Name Length (Technically Significant, But Not Really)
Both humans and AI models averaged about 5 characters per variable name. The statistical test said there was a "significant" difference, but when you look at the actual data, they're nearly identical. All four groups (human, ChatGPT, DeepSeek, Qwen) name variables the same way. AI has picked up on this stylistic practice.
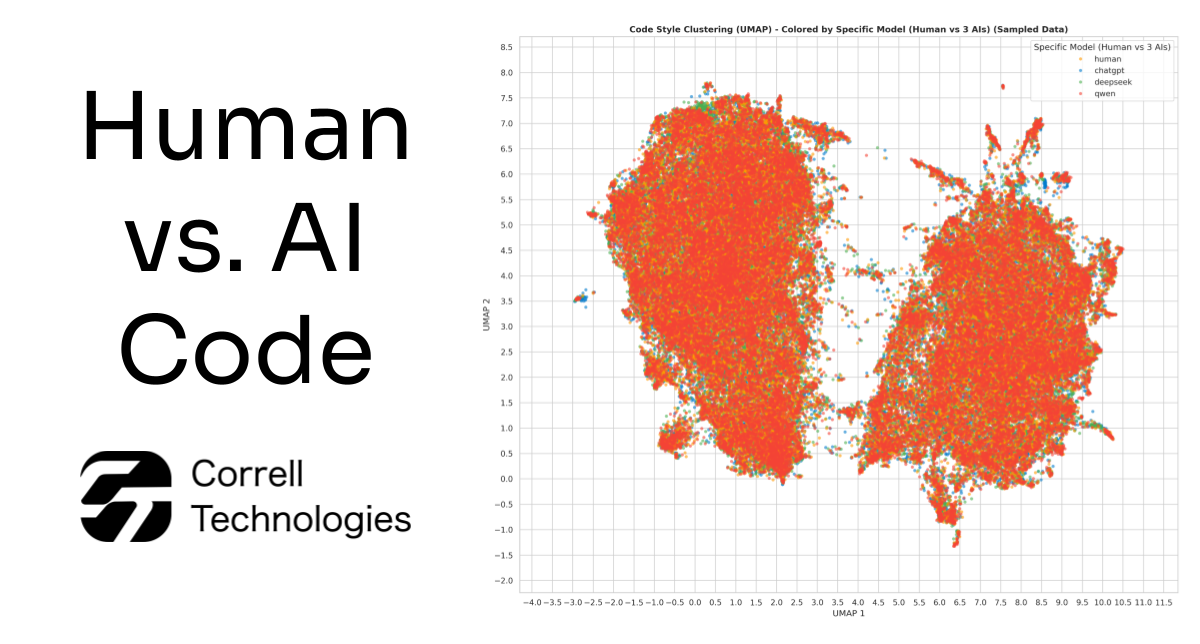
6. Code Style Clustering (UMAP Analysis)
We converted every code sample into a mathematical representation capturing its semantic meaning and logic, then visualized thousands of samples in 2D space. If human and AI code were fundamentally different in how they solve problems, they'd cluster into separate groups. As seen in the figures, human code and AI code were completely intermixed across the entire space. You cannot tell them apart based on meaning. Despite all the stylistic differences we found (line length, indentation, comments), when it comes to the actual problem-solving approach and algorithmic logic, AI and humans are writing the exact same code.
AI-generated code has clear stylistic fingerprints. It writes shorter lines, avoids deep nesting, and has its own style when compared to human generated code. However, these are just surface-level formatting choices. At the semantic level, where it actually matters, AI code is indistinguishable from human code. The algorithms are equivalent, the logic is sound, and the approaches to problem-solving are identical.
AI writes shorter lines and doesn’t value indentation as much as humans. These are detectable signatures which a classification model could catch. At the same time, the logic, the logic and problem-solving approach is nearly identical in meaning. AI is writing code that's functionally and semantically equivalent to what experienced developers produce.
Although there is an observable difference between AI and human-written code, models are improving rapidly. The stylistic tells we identified could disappear quickly. The fundamental finding, that AI can match human semantic reasoning in code, represents a threshold we've already crossed.
As discussed in previous articles, the future of software development isn't about replacing developers with AI. It's about redefining the developer's role. AI handles implementation while humans serve as architects, decision-makers, and quality gatekeepers. AI generates the code while humans define requirements, make architectural decisions, understand business context, and control creativity.
At Correll Technologies, we understand AI agents, automation, and the latest and greatest in technology. If you're interested in building AI-powered applications, exploring agentic workflows, or integrating systems into your infrastructure, reach out to us at contact@correlltechnologies.com.